You have 2 free member-only stories left this month.
begin quote from:
Auto-Encoder: What Is It? And What Is It Used For? (Part 1)
A Gentle Introduction to Auto-Encoder and Some Of Its Common Use Cases With Python Code
Background:
Autoencoder is an unsupervised artificial neural network that learns how to efficiently compress and encode data then learns how to reconstruct the data back from the reduced encoded representation to a representation that is as close to the original input as possible.
Autoencoder, by design, reduces data dimensions by learning how to ignore the noise in the data.
Here is an example of the input/output image from the MNIST dataset to an autoencoder.
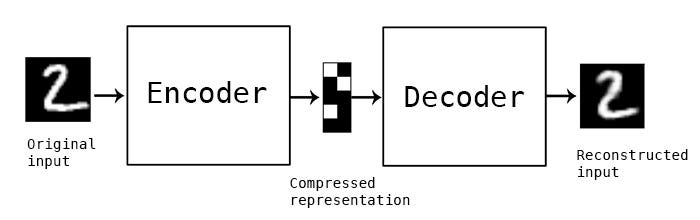
Autoencoder Components:
Autoencoders consists of 4 main parts:
1- Encoder: In which the model learns how to reduce the input dimensions and compress the input data into an encoded representation.
2- Bottleneck: which is the layer that contains the compressed representation of the input data. This is the lowest possible dimensions of the input data.
3- Decoder: In which the model learns how to reconstruct the data from the encoded representation to be as close to the original input as possible.
4- Reconstruction Loss: This is the method that measures measure how well the decoder is performing and how close the output is to the original input.
The training then involves using back propagation in order to minimize the network’s reconstruction loss.
You must be wondering why would I train a neural network just to output an image or data that is exactly the same as the input! This article will cover the most common use cases for Autoencoder. Let’s get started:
Autoencoder Architecture:
The network architecture for autoencoders can vary between a simple FeedForward network, LSTM network or Convolutional Neural Network depending on the use case. We will explore some of those architectures in the new next few lines.
1- Autoencoder for Anomaly Detection:
There are many ways and techniques to detect anomalies and outliers. I have covered this topic in a different post below:
However, if you have correlated input data, the autoencoder method will work very well because the encoding operation relies on the correlated features to compress the data.
Let’s say that we have trained an autoencoder on the MNIST dataset. Using a simple FeedForward neural network, we can achieve this by building a simple 6 layers network as below:
The output of the code above is:
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 6s 103us/step - loss: 0.0757 - val_loss: 0.0505
Epoch 2/10
60000/60000 [==============================] - 6s 96us/step - loss: 0.0420 - val_loss: 0.0355
Epoch 3/10
60000/60000 [==============================] - 6s 95us/step - loss: 0.0331 - val_loss: 0.0301
Epoch 4/10
60000/60000 [==============================] - 6s 96us/step - loss: 0.0287 - val_loss: 0.0266
Epoch 5/10
60000/60000 [==============================] - 6s 95us/step - loss: 0.0259 - val_loss: 0.0244
Epoch 6/10
60000/60000 [==============================] - 6s 96us/step - loss: 0.0240 - val_loss: 0.0228
Epoch 7/10
60000/60000 [==============================] - 6s 95us/step - loss: 0.0226 - val_loss: 0.0216
Epoch 8/10
60000/60000 [==============================] - 6s 97us/step - loss: 0.0215 - val_loss: 0.0207
Epoch 9/10
60000/60000 [==============================] - 6s 96us/step - loss: 0.0207 - val_loss: 0.0199
Epoch 10/10
60000/60000 [==============================] - 6s 96us/step - loss: 0.0200 - val_loss: 0.0193As you can see in the output, the last reconstruction loss/error for the validation set is 0.0193 which is great. Now, if I pass any normal image from the MNIST dataset, the reconstruction loss will be very low (< 0.02) BUT if I tried to pass any other different image (outlier or anomaly), we will get a high reconstruction loss value because the network failed to reconstruct the image/input that is considered an anomaly.
Notice in the code above, you can use only the encoder part to compress some data or images and you can also only use the decoder part to decompress the data by loading the decoder layers.
Now, let’s do some anomaly detection. The code below uses two different images to predict the anomaly score (reconstruction error) using the autoencoder network we trained above. the first image is from the MNIST and the result is 5.43209. This means that the image is not an anomaly. The second image I used, is a completely random image that doesn’t belong to the training dataset and the results were: 6789.4907. This high error means that the image is an anomaly. The same concept applies to any type of dataset.
2- Image Denoising:


Denoising or noise reduction is the process of removing noise from a signal. This can be an image, audio or a document. You can train an Autoencoder network to learn how to remove noise from pictures. In order to try out this use case, let’s re-use the famous MNIST dataset and let’s create some synthetic noise in the dataset. The code below will simply add some noise to the dataset then plot a few pictures to make sure that we’ve successfully created them.
The output of the code above is the image below, which is pretty noisy and fuzzy:


In this example, let’s build a Convolutional Autoencoder Neural Network. I will walk through each line of building the network:
First, we define the input layer and the dimensions of the input data. MNIST dataset has images that are reshaped to be 28 X 28 in dimensions. Since the images are greyscaled, the colour channel of the image will be 1 so the shape is (28, 28, 1).
The second layer is the convolution layer, this layer creates a convolution kernel that is convolved with the layer input to produce a tensor of outputs. 32 is the number of output filters in the convolution and (3, 3) is the kernel size.
After each convolution layer, we use MaxPooling function to reduce the dimensions. The (28, 28, 32) is reduced by a factor of two so it will be (14, 14, 32) after the first MaxPooling then (7, 7, 32) after the second MaxPooling. This is the encoded representation of the image.
input_img = Input(shape=(28, 28, 1))
nn = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
nn = MaxPooling2D((2, 2), padding='same')(nn)
nn = Conv2D(32, (3, 3), activation='relu', padding='same')(nn)
encoded = MaxPooling2D((2, 2), padding='same')(nn)The code below is the reconstruction part of the original digits. This is where the network actually learns how to remove the noise from the input images. We use UpSampling function to rebuild the images to the original dimensions (28, 28)
nn = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
nn = UpSampling2D((2, 2))(nn)
nn = Conv2D(32, (3, 3), activation='relu', padding='same')(nn)
nn = UpSampling2D((2, 2))(nn)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(nn)Now, the last remaining step is to create the model, compile it then start the training. We do this by running:
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta',loss='binary_crossentropy')
autoencoder.fit(x_train_noisy, x_train,
epochs=50,
batch_size=256,
validation_data=(x_test_noisy, x_test))After the training is complete, I try to pass one noisy image through the network and the results are quite impressive, the noise was completely removed:


If you scale the ConvNet above, you can use it to denoise any type of images, audio or scanned documents.
In this part of the article, I covered two important use cases for autoencoders and I build two different neural network architectures — CNN and FeedForward. In part 2, I will cover another 2 important use cases for Autoencoders. The first one will be how to use autoencoder with a sequence of data by building an LSTM network and the second use case is a called Variational Autoencoder (VAE) which is mainly used in Generative Models and generating data or images. Stay tuned!
Sign up for The Daily Pick
By Towards Data Science
Hands-on real-world examples, research, tutorials, and cutting-edge techniques delivered Monday to Thursday. Make learning your daily ritual. Take a look
No comments:
Post a Comment